
具身智能创业者图鉴:科学家们,从象牙塔走向修罗场

编者按:
在具身智能创业浪潮中,创始人们的背景与路径,决定了企业的技术走向与商业气质。
真格基金曾把创业者分为四类:小天才、老司机、科学家、操盘手。
这一分类启发我们,试图以此为框架,梳理具身智能领域的创业人群,开启具身智能公司群像专题。
科学家是高校教授、研究员与长期从事技术研发的人,代表着最前沿的学术力量。
老司机是连续创业者,过往经历让他们在起伏中更懂得如何把握节奏;
操盘手是来自大厂的高管,把成熟的方法论和资源带入新战场;
小天才则是年轻的 95 后创业者,以锐气和独特视角,激发出不同寻常的可能性。
在不同出身、不同路径的交汇中,我们或许能更清晰地理解具身智能的创业版图,以及它正在被塑造的未来。
当然,具身智能赛道上远不止这四类创业者,还有更多派别正在形成,这个系列,也将持续记录他们共同勾勒的具身智能全景。
作者 | 向欣
在创业早期,创始团队的光环往往是投资人最看重的因素。
放在具身智能行业,这种光环最盛的,正是从高校与科研机构走出来,长期从事技术研发的科学家们。
据 IT 桔子统计,2025 年上半年机器人公司融资榜单前五名分别是银河通用、新石器无人车、元鼎智能(泳池机器人)、自变量机器人、宇树科技。
剔除与具身智能概念关联较弱的新石器、元鼎智能后,一个耐人寻味的现象是:银河通用、自变量机器人这两家「科学家气质」浓厚的企业,融资规模甚至超过了老牌机器人公司宇树科技。
这一定程度上说明了科学家类企业在资本市场上的耀眼光芒。
在我们统计的具身智能赛道 32 家核心公司中,有 16 家由科学家创立或主导。他们出身清华、北大、上海交大、浙大、哈工大,或是海外的伯克利、斯坦福等名校。
这群人曾经的舞台在实验室与学术会议上,成果是论文、代码与原型机。但如今,他们走向产业前线,把机器人从象牙塔拉出来,推向工厂、家庭与社会。
科学家类代表着最前沿的学术力量,也承担着最艰难的任务:科研向商业的转化。前者是他们的优势所在,后者是他们创业路上最大的不确定性。
他们发展出不同的技术路径,既有共识,也有分歧。
 清华系人才成主力
清华系人才成主力
我们梳理了 16 家由具身智能科学家类创业公司的团队背景,统计出 32 位核心创业者。他们的学术背景主要集中在五所国内外顶尖高校与科研机构:清华大学、浙江大学、中国科学院、哈尔滨工业大学、斯坦福大学。

究其原因并不复杂。上世纪 90 年代,中国就已启动智能机器人相关研究,而清华、浙大、中科院、哈工大是最早一批设立机器人项目、实验室或研究所的机构,研究方向涵盖机械设计、机器人控制、智能感知等关键领域。
清华大学 1985 年成立了国内首个智能机器人实验室。2004 年,清华机器人足球队成立,后来发展为在 RoboCup 屡获佳绩的「清华火神队」。加速进化联合创始人、首席科学家赵明国正是「清华火神队」的创始人,并长期带队参赛。
浙江大学 2006 年开始人形机器人研究,推出了「悟空」系列,攻克了动态平衡、全身协调控制等关键难题。「悟空 I」甚至能与人类或机器人进行上百回合的乒乓球比赛。

中国科学院下属的沈阳自动化研究所被誉为「中国机器人事业的摇篮」,1989 年,依托于沈阳自动化研究所的中国科学院机器人学开放研究实验室正式成立,后该实验室在 2007 年获批为机器人学国家重点实验室。
斯坦福大学则更早,在上世纪 60 年代便成立人工智能实验室,探索机器人与 AI 的结合。
技术积累还可以从专利窥见一斑。新战略产业研究所数据显示,清华、哈工大、浙大在人形机器人相关专利申请上分别排第一、三、四名;另有 IncoPat 全球专利数据库的数据显示,在人工智能领域,浙大、清华的专利申请量分列全国第一和第二。
而从公司创业团队目前或曾经的任职机构来看,清华大学、南方科技大学成为孵化科学家类企业的主要基地。

从这些统计中,可以明显看出:清华系人才是科学家类企业的中坚力量。
目前,至少有四家科学家类企业直接源自清华:加速进化、星动纪元、星海图、千诀科技。逐际动力首席科学家潘佳、大寰机器人创始人孙杰、银河通用创始人王鹤等,也都是清华校友。
除了清华这所高校本身在机器人领域积淀已久,培育出大量人才的因素外,清华系投资机构对于培育本校企业也起到了至关重要的作用。比如,水木清华校友基金便多次投资加速进化等清华背景团队。
对于科学家类企业来说,他们能够依托高校科研资源和基金,直接接触国际最前沿的技术,为科研成果转化提供直接助力。
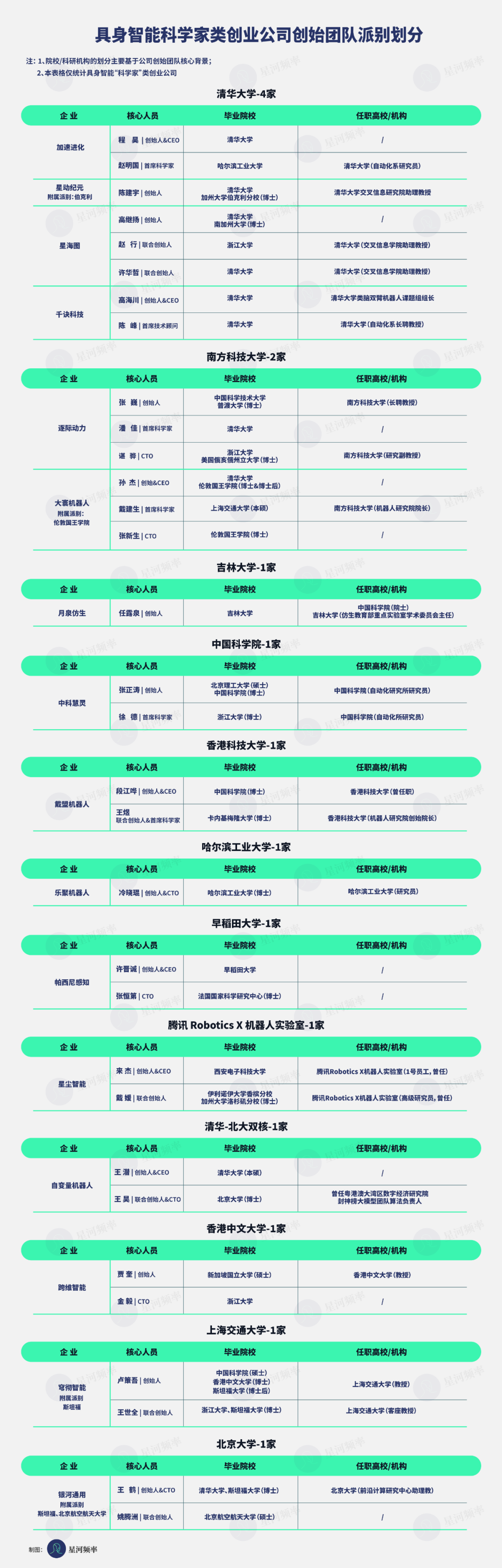
在人才方面,多数科学家类企业也有独特的优势,博士生、硕博后、实验室助研往往成为创业公司最初的员工,形成天然的团队延展。
更深层次的,是学术网络的传导。导师推荐、联合实验室、国际学术圈交流——这些关系构成了科学家类创业背后的看不见的脉络。
在融资层面,这种网络也很关键。投资人往往相信「清华系」「斯坦福系」的创业者,因为这些名字本身意味着研究深度和技术积累。
 技术理想主义驱动的产品布局
技术理想主义驱动的产品布局
虽然都强调技术驱动,但科学家派企业在产品和路线选择上,分化为三大类:
本体/小脑派:专注于机器人本体与运动、感知能力,代表企业有月泉仿生、加速进化、帕西尼感知。
全栈派:覆盖「本体+小脑+大脑」,试图掌握完整生态。代表企业有星动纪元、星海图、逐际动力。
大模型/零部件派:不做整机,而是专注具身大模型或关键零部件,如千诀科技、戴盟机器人、大寰机器人。
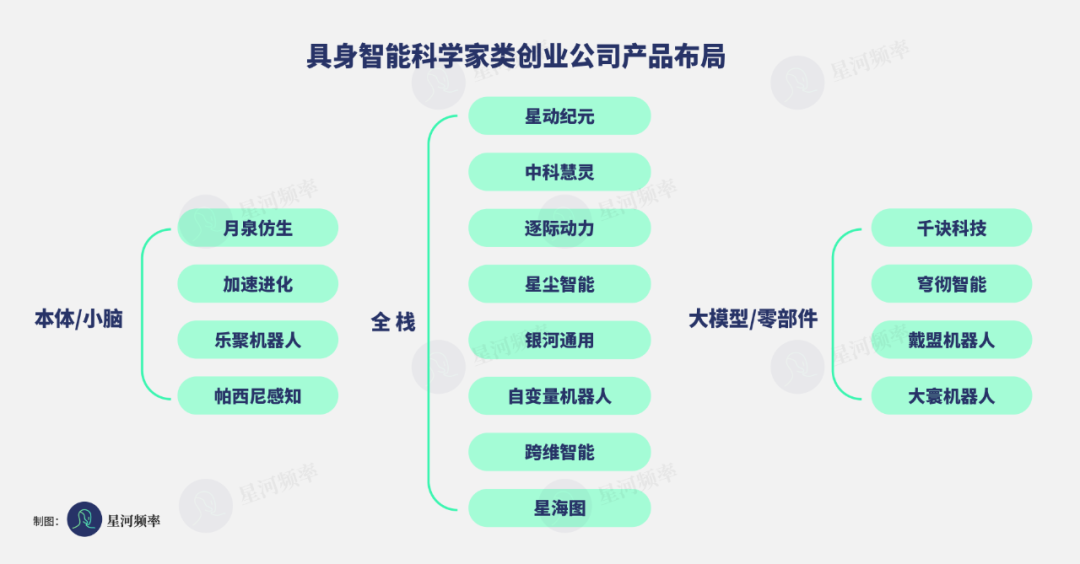
可以看到,大多数科学家派企业倾向于走全栈路线。这不仅是因为机器人系统软硬件耦合度高,更反映出学院派的技术偏好:他们更愿意从系统层面出发,构建完整链条来实现技术落地。
这种「终局导向」还体现在选择开发全尺寸人形机器人。除了加速进化主要研发 1.2 米的小尺寸机型,其他多数企业研发的都是 1.6 米以上、接近成人体型的全尺寸机器人。
这种选择的背后,是他们希望机器人能真正适应人类环境、具备强负载和复杂操作能力,从而在更广阔场景中实现通用性。
另一个值得注意的现象是:在全栈派企业中,更侧重研发大模型的团队多数选择轮式人形机器人,如银河通用、自变量机器人、跨维智能、星海图。
相比双足,轮式降低了研发门槛和人力投入,使有限的团队资源更集中于大模型研发。
总体来看,科学家派在硬件与全栈方面各有探索,但真正拉开差距的,是在大模型上的突破。
重点研发具身大模型,且最受业界关注的有四家企业:星动纪元、银河通用、自变量机器人、星海图。
这四家企业的共性是,不约而同地做了端到端 VLA 模型。技术思路与 Figure、PI (Physical Intelligence)、NVIDIA 等国际前沿研究同步。
他们普遍认为,只有端到端大模型才能实现任务泛化,避免传统分层架构的割裂。这一思路也与自动驾驶领域正在验证的技术范式一致。
无论是专注本体的小而美,还是覆盖全栈的体系化,抑或切入大模型与零部件的聚焦型探索,科学家派企业都在用各自的学术积累寻找产业落点。
尽管路径不同,但几乎所有团队都在走向同一个共识——具身大模型是未来的「核心战场」。因此,科学家派的差异,最终可能集中体现为对大模型的理解与实践。
 具身大模型的路线差异
具身大模型的路线差异
具身大模型的本质竞争力在于模型算法和数据体系。
从模型算法上看,星动纪元、银河通用、自变量机器人、星海图四家企业中,只有自变量机器人强调其模型实现了大小脑统一,而其他企业都使用了类似双系统的架构,将高层次的理解规划、低层次的运动控制分为一个系统中的不同模块,与 Figure AI 的 Helix 模型,PI 的π0 模型类似。
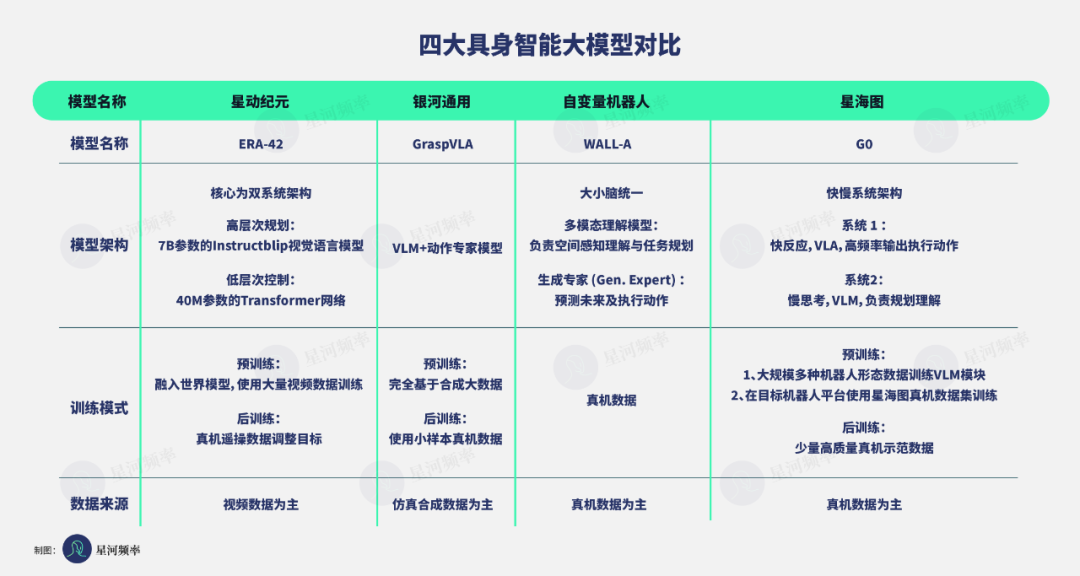
星动纪元有两个特点:
一是在大模型中,融入了世界模型,增强机器人对物理世界的理解;
二是借鉴 Sora 思路,利用 AIGC 生成式技术,通过生成视频,帮助机器人预测未来场景,让机器人「看着答案」行动,大大增强泛化能力。
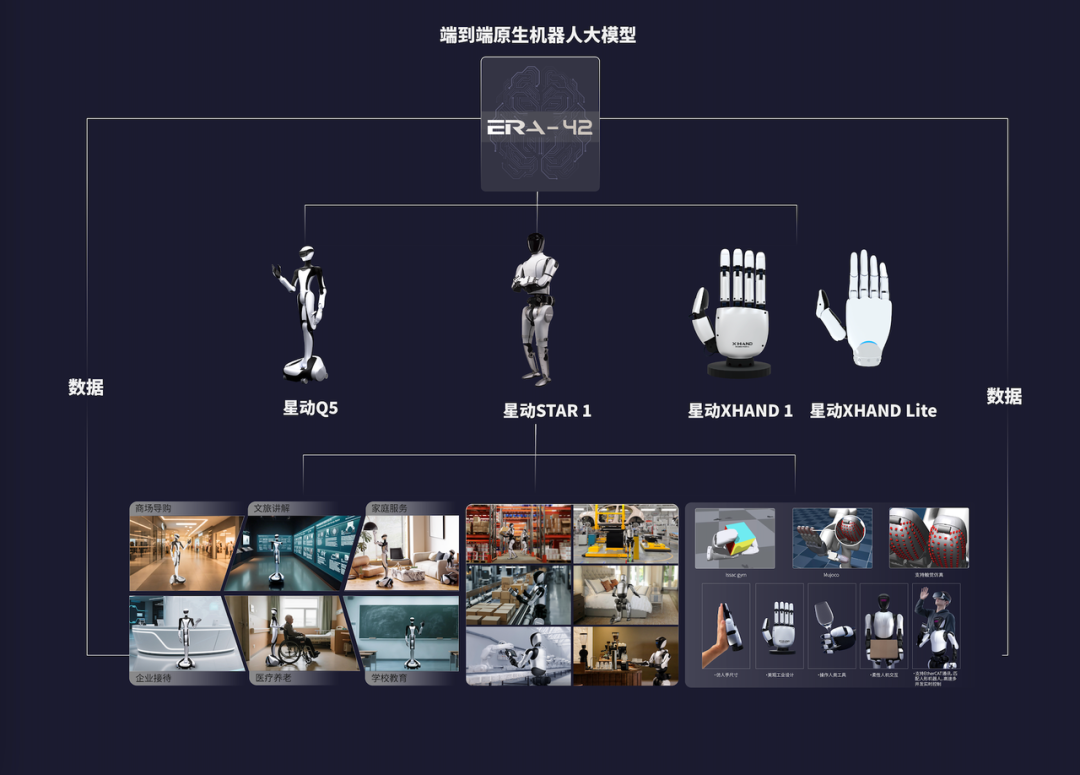
目前的 ERA-42 是集视觉、理解、预测、行动为一体的模型,可实现同一个端到端 VLA 模型控制高自由度人形机器人的全身灵巧操作,语音命令即可完成上百种复杂操作,包括柔性物品分拣、扫码,使用螺钉枪、移液器等。
银河通用的模型 GraspVLA 架构则与 PI 的π0 模型基本一致,同样由 VLM 和一个基于流匹配的动作专家模型组成。
GraspVLA 的最大特点是泛化性极强,是全球首个仅需预训练就能实现零样本(Zero-Shot)泛化的模型,可适应高度、平面位置、物体类别、光照、干扰物、背景等环境条件的变化,且具备自主决策能力与强抗干扰能力。
基于 GraspVLA,银河通用还推出了面向零售商业化场景的端到端大模型 GroceryVLA,在商品种类繁杂、密集堆叠的货架场景中,无需针对每种商品单独调参,抓取全品类商品,并且零场景预采集要求,部署极其便捷。

自变量机器人的端到端通用具身大模型 WALL-A 同样具备泛化性、通用性强的特点,在不久前的 WRC 上展示了制作香囊、家务整理、分拣快递、工业组装(仅用不到两天时间学会组装皮带)的任务,对柔软物品、不断变化的环境、不同外观的物品都具有强大的适应性。

不过,相比其他公司的模型,自变量的模型对机器人所接受到的各种信息整合程度更深,实现了端到端的信息融合。
自变量机器人整合信息的具体方式为:将所有输入模态,包括多视角图像、文本指令与机器人实时状态,通过各自的编码器转化为统一的 token 序列,使机器人在视觉、语言和动作等多种信息通道间实现高效对齐,显著提升了模型在超长序列任务中的上下文推理与自我反馈能力。
在数据体系方面,四家企业虽然都会将视频、语言、动作、遥操作等多模态数据混合使用,但侧重点有所不同,从而形成了两种不同的数据策略。
一种是规模优先型,强调低成本、大规模数据积累,以量取胜,目标是支撑具身大模型的端到端训练,达到「大力出奇迹」的效果。星动纪元、银河通用属于这一类。
星动纪元使用视频数据对模型进行预训练,视频数据中包括大量互联网人类视频与 AI 生成视频,易于获得。
而银河通用坚持仿真合成数据路线,研发出一套针对端到端 VLA 模型预训练的全仿真合成数据生产管线,在短短一周内就能生成全球规模最大的十亿级机器人操作数据集(包含视频-语言-动作三个模态)。
另一种是质量优先型。聚焦高质量真机数据,强调对模型泛化能力和学习效率的提升。星海图、自变量机器人选择了这一路线。
星海图构建了全球首个开放场景高质量真机数据集 Galaxea Open-World Dataset,覆盖住宅、厨房、零售和办公室等 50 种环境,总计包含 500 小时高质量移动操作数据,涵盖超过 150 种任务、1600 多种操作对象以及 58 种操作技能。
自变量机器人创始人王潜介绍,公司自研了一系列数据采集设备,有几十个模型支撑自变量机器人的数据系统。
王潜认为,在 Scaling Law 中,数据质量才是最核心的要素,其次是多样性,最后才是数量。他在大模型训练实践中发现,高质量数据往往几百几千条就能带来显著提升,而低质量数据即便上亿条,也可能让模型越学越差。
数据选择策略的不同,本质上是对具身智能发展瓶颈的不同判断。前者希望解决的是数据稀缺问题,后者希望解决的是数据有效性问题。
这也代表了科学家派企业在具身智能大模型上两种不同的认知:是依赖规模催生智能,还是通过高质数据夯实通向落地的基础。

技术优势和商业劣势,一同被放大
科学家作为具身智能赛道中最具技术含金量的力量,优势鲜明,短板也同样鲜明。
优势在于技术前瞻性,他们往往能比市场更早看到未来的技术发展方向。
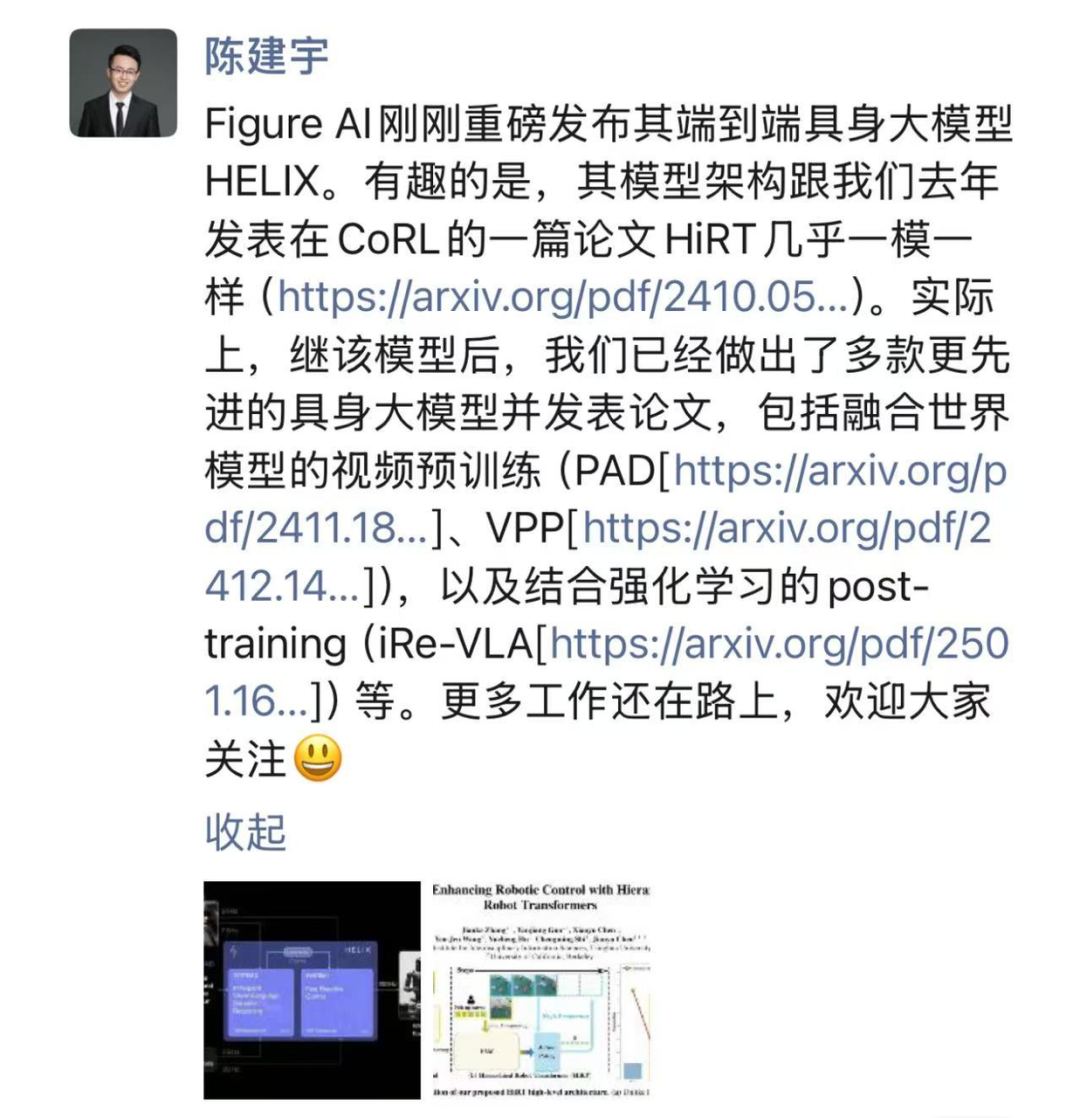
例如,星动纪元在 2024 年就将清华姚班团队提出的 HiRT 框架(星动纪元创始人陈建宇亦为 HiRT 论文作者之一)的快慢系统架构应用到自研的端到端原生机器人大模型 ERA-42 中;而 2025 年美国明星人形机器人企业 Figure AI 发布的 Helix 模型,恰好采用了与 HiRT 高度相似的架构。
自变量机器人也提前预判到了技术的走向。
王潜介绍,他们在 2024 年 10~11 月就着手研发 any-to-any 模型,实现多模态输入输出,还同期完成具身思维链(COT)研发。这与 Google Gemini robotics 2025 年 3 月公布的进展、以及近期 Physical Intelligence(PI)公布的π0.5 模型技术方向高度一致,与国际顶尖水平同步。
劣势在于对商业化的敏感性可能不足。科学家创始人习惯学术逻辑,追求完美解法,而市场的要求往往是够用就好。
如何平衡技术理想与场景要求,是一个难题。
目前科学家类具身智能企业的商业化路径主要有三种。
一是覆盖多种场景,包括家庭、工业、商业服务等,并参与场景开发的企业,包括星动纪元、乐聚机器人、自变量机器人等。这也是多数科学家类企业选择的打法。
这种策略在展示人形机器人通用性时颇具吸引力,也符合行业对机器人应用终局的期待,但一旦落到商业化层面,可能难以找到核心落脚点来实现闭环,容易陷入「样样通,样样松」的困境。
二是已经有初步聚焦的场景或技能方向。
如加速进化,专注机器人运动性能的提升,主要面向科研场景销售;银河通用主要聚焦「移动-抓取-放置」的闭环操作,应对零售与工业场景中的大量「抓—放—移动」式作业。
三是不直接做场景开发,提供具身智能基础设施的企业,比如星海图、逐际动力。他们主要面向各类开发者提供基础的通用软硬件(包含具身通用大模型+机器人本体),让个人开发者或场景方成为开发应用的人。
目前具身智能的应用仍处在探索阶段,商业路径尚无定论,也难言优劣。
但具身智能的应用落地对一家企业的真正考验,已不仅是技术本身,而是能否在组织搭建、资金运用和战略落点上展现持续能力。
技术突破只是起点,如何把突破转化为可规模化的产品与市场,才是决定生死的分水岭。
前期,科学家派创业者往往凭借学术光环与技术积累,能迅速获得资本的青睐。
但随着公司进入商业化阶段,投资人关注的重心转向更直接的指标:订单数量、客户结构、落地案例。这时如果缺乏清晰的商业模型和市场抓手,融资链条会趋紧,企业的发展甚至可能陷入停滞。
科学家派的优势和短板会被同时放大:他们站在技术浪潮的最前端,却也必须面对市场的冷峻检验。
未来,能否在保持科研前瞻性的同时找到明确的商业锚点,将决定科学家派究竟是引领具身智能的「开路者」,还是被迫止步于实验室与 Demo 阶段的「先行者」。





欢迎点击“阅读原文”加入星河频率知识星球。
0
分享
好文章,需要你的鼓励










参与评论
请您注册或者登录星河频率社区账号即可发表回复
去登录
相关评论(共0条)
查看更多评论