
从「单一动作」到「包揽全流程」:拆解 Motubrain 双榜第一背后的杀手锏

今天,很多机器人会遇到一个略显尴尬的窘境:你让它「帮忙做一顿饭」。它听懂了,然后呢?然后就没有然后了。
大多数机器人会卡在第一步:不知道食材放哪,不知道灶台怎么开,更别提中途盐放多了该如何调整。这不是因为它笨,而是它的大脑从来没有被设计来处理一整条任务链。
过去几年,机器人行业确实进步飞快:
关节更灵活了、传感器更密了、走路也更稳了。可一旦把机器人扔进真实环境里,很多系统立刻就「翻车」。
问题不在硬件,而在大脑:能感知的不懂行动,会行动的又看不懂环境变化。这种能力割裂,正是机器人迟迟无法大规模落地的根源。
也正因如此,近期一个动态值得关注:
一个名为 Motubrain 的模型,在 WorldArena 与 RoboTwin2.0 两个国际 benchmark 上同时拿下第一。
前者考察理解和预测世界的能力,后者衡量执行任务与泛化的水平,这两项长期被分而治之的能力,在同一模型上同时取得领先。
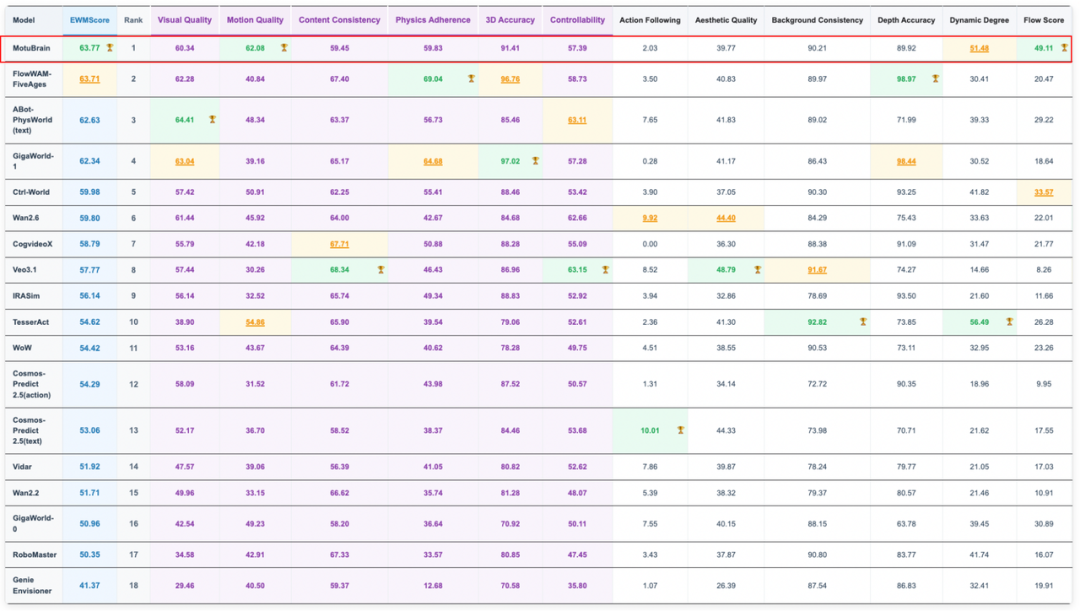
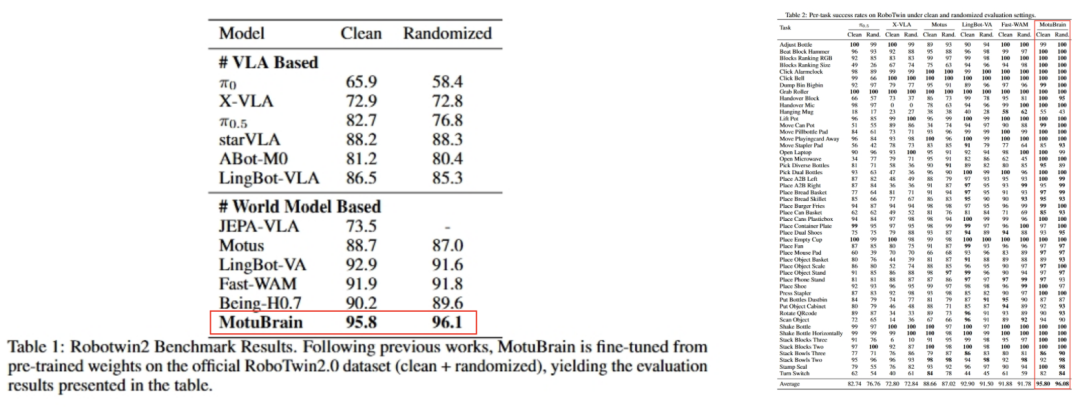
这不是巧合,而是体现出 AI 进化进入第三阶段的代际跃迁。
此前,从第一阶段的语言模型(理解世界),到第二阶段的视频模型(生成世界),AI 的能力一直停留在「认知」和「表达」的层面;
而 Motubrain 所代表的第三阶段,即进一步迈向「行动于世界」(Act in the World),让模型不仅能够理解和生成,还能够在物理世界中持续做出决策并驱动行动。
而这种能力形态,在技术路径上正对应着一种新的模型范式:
世界行动模型(World Action Model,WAM)。它不再将「理解世界」和「执行动作」拆分为多个模块,而是试图在同一模型中完成从认知到行动的闭环。

这件事的价值,不只是一次性能登顶,更是一次路径验证,即机器人行业的竞争,正在从「谁更会动」转向「谁更会做事」。
而后者能否成立,归根结底是一个问题:我们能否造出真正通用的机器人大脑?
 从单一动作到包揽全流程,
从单一动作到包揽全流程,
机器人必须跨越的「一道坎」
如果把今天的机器人拆开看,单点能力其实已经相当不错。
比如抓取一个固定位置的物体,成功率可以轻松超过 95%;在无障碍走廊里导航,路径规划丝滑流畅;识别常见物品,视觉大模型早已不在话下。
单看这些指标,很容易得出一个乐观的结论:机器人似乎已经准备好进入真实世界了。
然而,现实给出的答案恰恰相反。一旦把机器人从实验室搬到家庭、餐厅、仓库等开放环境,绝大多数系统会迅速「露馅」。
问题出在哪?拆开来看,每一个子任务,如抓取、放置、旋转、移动,把这些动作串成一个连续的任务链,系统就开始崩溃。
这恰恰揭示了当前机器人智能的核心瓶颈:
大多数系统仍然是围绕「单一任务」构建的。抓取是一个抓取模型,导航是一个导航模型,操作是一个操作模型。它们像是拼图一样被强行组合在一起,彼此之间缺乏统一的状态认知和决策协同。这种模块化拼接的方式,在结构化环境中或许还能勉强运行,一旦遇到动态变化或长程任务,系统的脆弱性就会暴露无遗。
这也是为什么,即便机器人能翻跟头,却依然无法真正在工厂流水线上打工的根本原因——因为缺乏连续决策的统一大脑。
要知道,现实世界中的任务,本质上是一个连续的决策过程,从准备、执行到收尾,中间伴随着环境变化、状态偏移和意外干扰。
而在这一问题上,Motubrain 给出了一种截然不同的切入方式。它不是围绕「优化某一个动作」来迭代,而是围绕「行动」构建统一的智能体系。
它将自己定义为通用世界行动模型(World Action Model, WAM),核心主张可以概括为一句话:为行动而生。
但这里的「行动」,并不是像传统的 VLA(视觉-语言-动作)只是拟合动作,Motubrain 是基于对世界规律的理解来驱动行动。从拟合到理解并预测,是 Action Model 的核心进化点。
这意味着,Motubrain 从一开始就不是冲着抓得更准或走得更稳去的,而是奔着完整做成一件事来的。
以家庭餐食场景为例:
它需要处理的是「准备—服务—收拾」的完整任务链,而不是其中的某一个环节,包括支持双手协同处理食材,根据炉灶温度变化调整操作节奏;要在调料打翻时重新规划清理步骤,在发现食材缺失时灵活替换方案……所有这些,都在同一个模型内部完成,不靠拼接多个独立模块来勉强凑合。
从这个角度看,Motubrain 试图解决的根本问题,就是机器人能不能连续完成一个任务,这正是通向通用机器人大脑必须跨越的那道坎。
 不止于双榜第一,
不止于双榜第一,
生数科技背后的完整布局
过去一段时间,机器人智能的发展大致沿着两条路线各自狂奔。
一条叫「世界模型」,核心是让机器理解环境、预测状态变化;
另一条叫「动作模型」,聚焦任务执行与操作能力。两条路线各自积累了不少成果,但一个尴尬的事实是:它们长期处于割裂状态。
这种割裂带来了一个典型困境。擅长世界模型的系统,往往能准确描述正在发生什么、接下来可能发生什么,可一到需要实际动手操作时就束手无策;
而擅长动作模型的系统,虽然能把单一任务执行得行云流水,却对环境变化缺乏预判,稍有扰动就容易出错。
Motubrain 的出现,正是在尝试缝合这道裂痕。
它所代表的技术路径,不再把预测世界和驱动行动当作两个独立的阶段来处理,而是在同一个模型中同时完成这两件事。这种统一范式落实到能力层面,可以进一步拆解为四个维度,也是 Motubrain 最核心的差异化标签:
首先是一脑多能,应对多种任务。
比如整理沙发的过程中,机器人并不是简单地摆放物体,而是需要先识别衣物与杂物的差异,再完成分类与整理。
这一过程同时涉及视觉识别、语义理解与操作执行,本质上是多个子任务的融合,而不是单一动作的重复。
其次是一脑多型,适配多种本体。
事实上,Motubrain 并没有被限定在某一款机器人上运行,而是接入了不止一种硬件形态。
这意味着它并非为某一台设备量身定制,而更像是一个可以适配不同「身体」的统一智能底座,具备跨本体复用的能力。
第三是一脑贯通,长程任务一步完成。
以插花为例,机器人需要连续完成抓取花枝、定位花瓶、调整角度、插入,再到拿起喷壶浇水、移动花瓶等多个动作。
这些操作并非被拆解后逐个调用,而是在同一模型中被连续执行,形成一条完整的动作链路。
最后是一脑预见,实现动态决策。
当需要机器人煮火锅捞食材,但出现「捞空」的情况时,机器人不会停在当前结果,而是能够重新判断位置并再次尝试。
这种基于当前状态的修正过程,体现出其能够根据环境变化不断调整后续动作,而不是机械执行既定指令。
从这些具体操作可以看到,这四个维度并不是抽象能力,而是直接体现在机器人对多任务处理、多本体适配、长程任务执行以及动态调整能力上的统一表现。
事实上,这些维度的能力并非停留在纸面上。在生数科技最新释出的实机视频中,Motubrain 已经展现出了极具震撼力的工业级落地潜力。
画面中,机器人完成了包括插花、整理沙发、舀取食材、倒果汁、调酒、整理洗漱台等一系列任务,其背后正是对机器人一脑多能、一脑多型、一脑贯通、一脑预见等不同维度能力等直观体现。
实际上,Motubrain 并不是孤立的模型发布,它背后对应的是生数科技一整套通用世界模型战略。
在长期的视频大模型技术积累基础上,生数科技构建了以通用世界模型(Foundation World Model)为核心底层、贯通数字空间与物理空间的双轨体系。
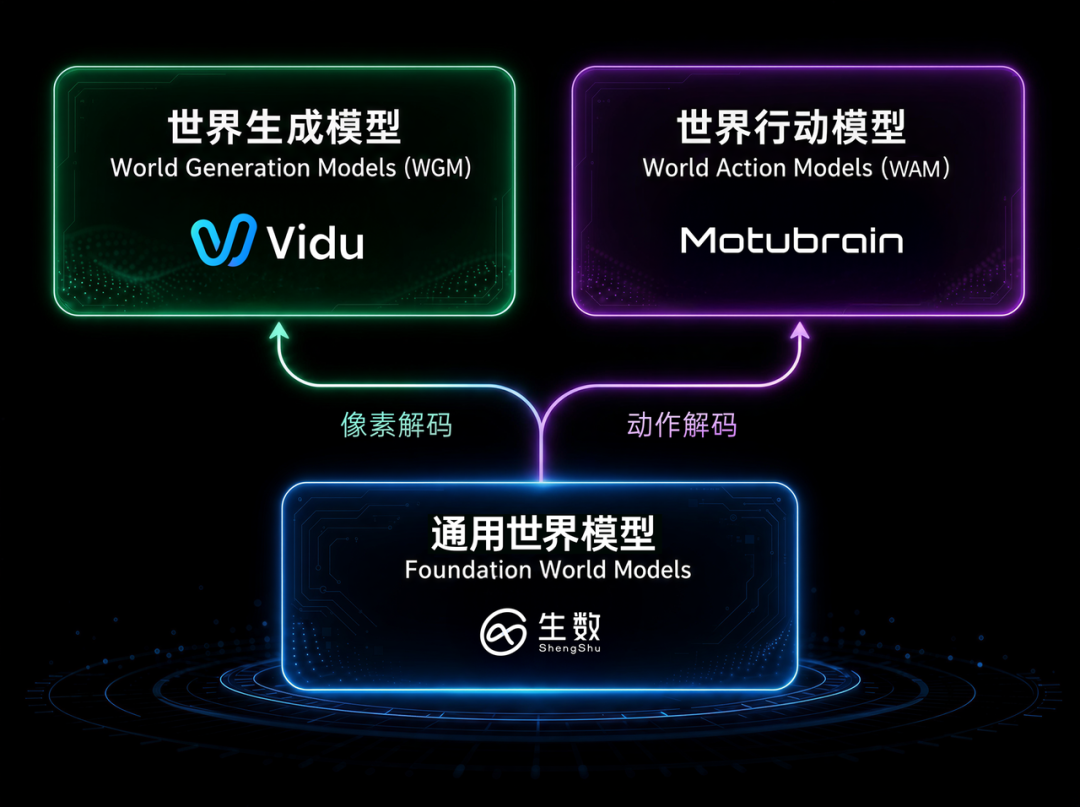
在数字空间,基于世界生成模型打造视频大模型 Vidu,推动 AI 在内容生成领域的落地;
在物理空间,基于世界行动模型构建 Motubrain,推动机器人从「模块化执行」走向「统一智能体」。
两条线共享同一底层能力,目标是打通「预测世界—生成世界—行动于世界」的完整闭环。
更重要的是,这套布局正在加速从技术走向产业。
生数科技近期已先后与无界动力、深朴智能等企业达成战略合作,将 Motubrain 的模型能力接入具体的机器人系统,推动其进入真实场景。
这意味着,生数科技正在围绕通用机器人大脑,加快形成从通用世界模型到机器人场景落地的完整布局。
回到开头那个问题:让机器人帮忙做一顿饭,它到底能不能做到?过去,答案是否定的。因为机器人只有身体,没有能理解世界并连续行动的「大脑」。
而今天,随着 Motubrain 在 WorldArena 和 RoboTwin2.0 上同时拿下第一,以及世界模型与动作模型在同一框架下走向统一,这个答案正在被改写。
当然,从榜单第一到真正走进千家万户,中间还有很长的路要走,包括真实世界的复杂度、数据的匮乏、算力的约束,都是必须翻越的山丘。
但至少方向已经清晰,当一台机器能够连续完成一整条任务链,能够预见变化并动态调整,能够在不同本体、不同场景间迁移能力,它就不再是一台预设程序的设备,而是一个名副其实的智能体。
这或许就是生数科技最大的价值所在,它不是给出了一个完美的答案,而是证明了一条可行的路。
而这条路径的意义,早已不止于机器人本身,它指向的是 AGI(通用人工智能)进入物理世界的关键一步。
随着与无界动力、深朴智能、星尘智能等合作的推进,这一路径也正从模型验证,逐步走向真实世界的商业落地当中。
https://www.shengshu.com/zh/motubrain
0
分享
好文章,需要你的鼓励










参与评论
请您注册或者登录星河频率社区账号即可发表回复
去登录
相关评论(共0条)
查看更多评论